
오버 피팅이란 학습 데이터에 모델이 과도하게 적응하여 새로운 데이터에 대한 분별력을 잃어버리는 현상을 말합니다.
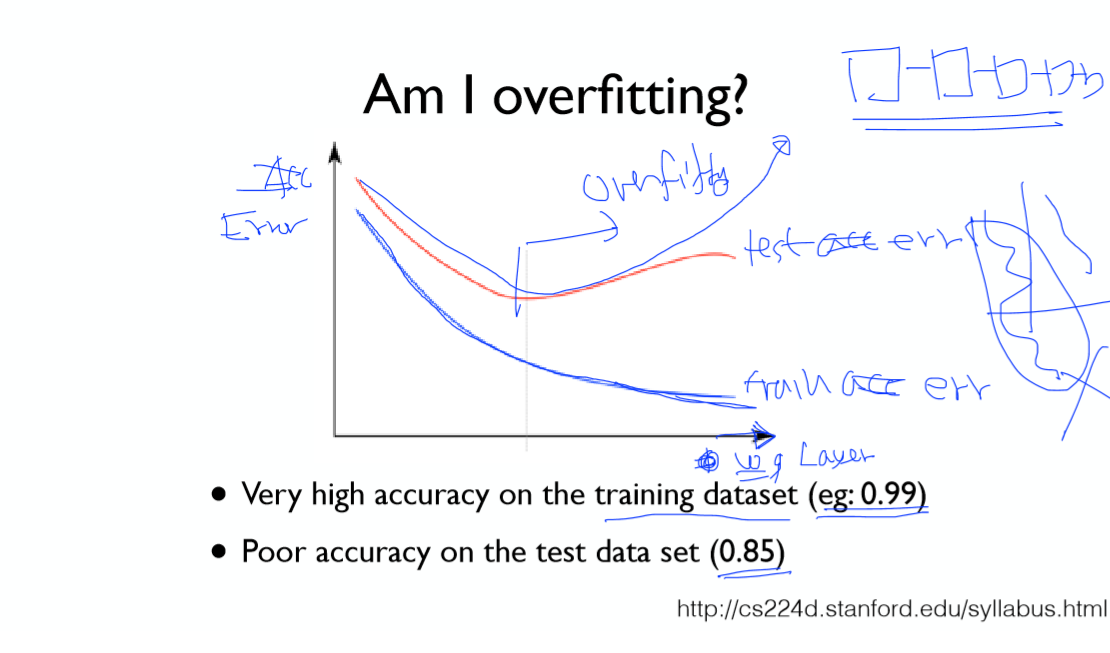
모델이 오버 피팅인지 알 수 있는 방법은 학습 데이터와 테스트 데이터의 정확도 차이를 보면 알 수 있습니다.
지난 시간에는 오버 피팅을 해결하기 위해 Regularization(일반화) (7장 참고) 를 이용했습니다.
이번 시간에는 Dropout기법을 알아보도록 하겠습니다.

Dropout

Dropout이란 학습 시 임의의 노드를 0으로 설정하는 방법입니다.
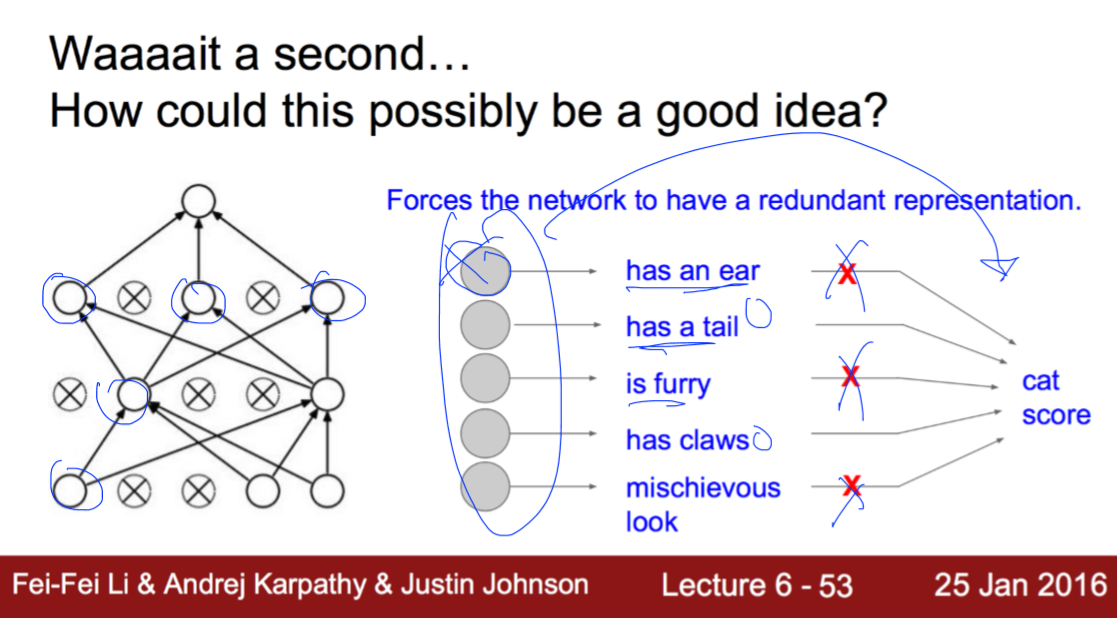
이 방법을 이용하면 특정노드에 모델이 의존적으로 바뀌는 것을 억제할 수 있다.
또한 학습 데이터에 의해 가중치들의 서로 동조화 되는 현상을 억제할 수 있고
모델 결합에 의한 투표효과(Voting)이 생기게 되고 학습의 성능이 개선된다고 한다.

*)한단을 더 만들어 dropout한걸 다음 layer로 보낸다.
*)0.7->70%만 참여해 30% OUT
Tensorflow에서는 Dropout을 이미 구현해 놓았다.
이 함수를 사용할때 우리는 Dropout비율을 잘 설정하면 된다.
주의할 점은 테스트를 할 때는 비율을 1로 설정해야 한다는 점이다.

앙상블이란 독립적으로 모델을 만든 뒤 각 모델을 학습시킨 후,
테스트 시 각 모델의 결과들을 합하여 최종 결과를 뽑아내는 방법을 말한다. (Voting)
이러한 방법을 통해 4~5%의 성능 향상을 얻을 수 있다.
(Dropout의 원리와 관련이 있다!)
'모두를 위한 딥러닝' 카테고리의 다른 글
| [DL] 모두를 위한 딥러닝 10-5 ReLu, Xavier, Dropout, Adam (0) | 2022.04.24 |
|---|---|
| [DL] 모두를 위한 딥러닝 10-4 NN LEGO (0) | 2022.04.05 |
| [DL] 모두를 위한 딥러닝 10-2 Initialize weights (0) | 2022.04.05 |
| * [DL] 모두를 위한 딥러닝 10-1 ReLU (0) | 2022.04.05 |
| [DL] 모두를 위한 딥러닝 9-4 Tensorboard 사용 (0) | 2022.04.05 |